Hands-on LLM Inference Bake-Off
18 May 2026, Taro LangnerAs the ecosystem around open-weight LLMs expands, so do its options for inference serving. Open-source software enables self-hosting these models on varied hardware, from outright GPU clusters to workstations, laptops and even smartphones.
This post shares a first-hand account of trying to get these models to speed, from self-hosting on local hardware to running inference serving on an H100 GPU using vLLM and SGLang.
Background
Modern frontier LLMs are rumoured to have trillions of parameters, requiring an entire rack of datacenter GPUs for serving.
In contrast, Small Language Models (SLMs) and Tiny Language Models (TLMs) can reach below 1B parameters, with memory footprints reduced further through aggressive quantization, compressed KV caches, lower context lengths and architectural innovations. The previous blog post shared a brief overview of this space.
Self-Hosting Experiments
Models like Gemma 4 E4B can run locally even on my six years old MacBook Pro with an M1 chip and 16GB of memory. At 4-bit quantization, it reaches about 16 tok/s using Ollama and almost 20 tok/s on MLX.
These throughput numbers are less impressive than the emergent capabilities it attains in this setup, however, running hot enough to potentially fry a sausage (at >70°C, especially when combined with Open WebUI).
Even my Android smartphone can run this model with the open-source Google AI Edge Gallery app. Its on-device, offline design is intriguing but also somewhat limiting.
Flexibility in tool use requires more tinkering for the local hosting setup. For web search, LangGraph offers some simple integrations for custom agentic harnesses that I have been experimenting with. For agentic coding, pi.dev (on which OpenClaw was built) offers a terminal-based, minimal coding agent harness that I have been running in a docker sandbox with a local RTX 3090 and larger models.
Ultimately, these setups might go a long way if I was suddenly cut off from proprietary APIs entirely. However, they also show some of the limitations of these smaller and aggressively quantized local models. Despite web search capabilities, the outputs from the simple LangGraph harness easily miss the mark and the reasoning traces can be quite revealing as to where the models go wrong. For agentic coding meanwhile, some of the aggressively quantized SLMs tend to produce typos and go down unproductive rabbit holes that larger, more capable models would typically manage to avoid.
Interestingly, self-hosting larger models would actually be more viable on newer Apple Silicon chips than on the RTX 3090 GPU. While the latter still wins out for compute-intensive training tasks, its 24 GB VRAM cannot beat the memory capacity of up to 512 GB of unified memory for pure inference tasks.
For much of this work here, while starved of my Claude usage limit, I ultimately settled on using OpenCode with OpenRouter to connect to different proprietary APIs. This setup feels barely distinguishable from Claude Code in capability now and models like DeepSeek V4 Flash run at low cost with surprisingly long context. But despite good pricing and flexibility, it also means entrusting its Chinese provider with all of the prompt data and code during development.
So what about genuinely self-hosting more beefy and capable models like this in a privacy-conscious and self-contained way, potentially even for multiple concurrent users?
Cloud-based Hosting
For this post, I wanted to see how much throughput I could get with the frameworks vLLM and SGLang. These open-source frameworks offer a range of different inference optimizations that could serve in production for an entire organization or large user base, even with an on-premise cluster.
Although I have no larger GPU to spare, there are several commercial offerings for serverless GPU rentals that typically bill by the second. The free monthly credit on Modal seemed just right for my purpose here, covering about 8 to 40 hours of experimentation, depending on the hardware selection.
I started out with a smaller GPU and model for prototyping, using an L4 GPU with 24GB and Qwen3.5-4B at bfloat16 precision for Experiments 1, 2 and 3. This turned out to be a wise choice, as the overwhelming majority of the credit budget was spent on dependency management and unexpected quirks of the individual frameworks. The resulting setup is not a strictly fair comparison, but good enough to play around with some of the core features already.
With HuggingFace Transformers (HFT) as baseline and vLLM and SGLang in place, my first goal was to get a hands-on feel for the different throughput numbers. For this, I set up a simple FastAPI web interface that could run each in their own container and show their streaming output in realtime. For the exact package versions and settings, see the implementation on GitHub.
Experiment 1: Baseline Run
Cold-starting the server backends takes a while, with about 5min for vLLM and 3min for SGLang. Under the hood, they compile CUDA kernels for the given GPU, perform CUDA graph capture for multiple batch sizes and sequence lengths and profile memory usage. This prompted me to set up little indicator lights for server status on the web UI.
To avoid an unfair advantage on repeated runs, where the KV cache contents could be kept in memory, I also disabled prefix caching for vLLM and radix caching for SGLang. All following experiments were done with at least two warmup runs.
Even in this simple setting with a single request, the initial wait is already worth it. Both vLLM and SGLang are well matched and on average beat the baseline by almost 50% higher throughput.
Experiment 2: Speculative Decoding
Next, I wanted to try multi-token prediction (MTP), which the Qwen 3.5 models support natively.
Just as with speculative decoding with a draft model, the speed-up here results from being able to quickly generate a sequence of draft tokens that the main model can verify all at once in parallel. All accepted draft tokens (and the correction for the first rejected speculative one) can be returned after one such step as opposed to producing them sequentially with the main model.
The Qwen 3.5 models are trained with a separate MTP head that predicts one speculative token. It can be run for multiple steps to generate a sequence of draft tokens, but for this experiment I chose a conservative setting of one at a time. Depending on the acceptance rate, this can yield up to two tokens for a single decode step.
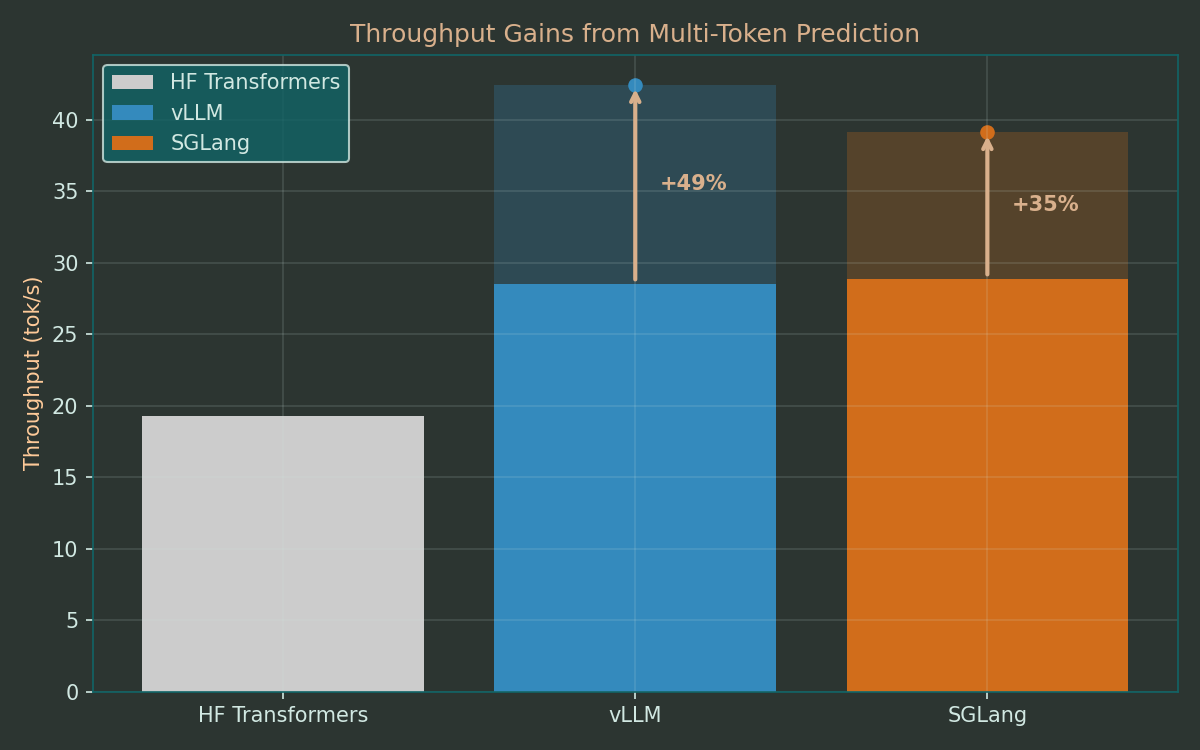
In this setup, vLLM and SGLang can increase their throughput with MTP by yet another 30-50%. Combined with their base advantage, this yields more than double the throughput of the baseline.
Experiment 3: Prefix Caching
Many use cases for LLMs involve recurring token sequences like system prompts, context retrieved by RAG and the history of multi-turn chats. With prefix caching, the memory blocks in KV cache can be managed to avoid recomputing its contents for these. With Automatic Prefix Caching in vLLM, or Radix Attention in SGLang, prefixes can even be shared between different sequences, both for speed and reduced memory consumption.
To test this feature, I added a checkbox to the web interface that adds a longer sequence in front of the input prompt before sending to the frameworks. For this, I chose the word ‘poem’ repeated 2000 times. I also turned off the multi-token prediction and enabled prefix caching. I started with three repetitions of the original short prompt before sending three requests with the longer, prefix-based prompt.
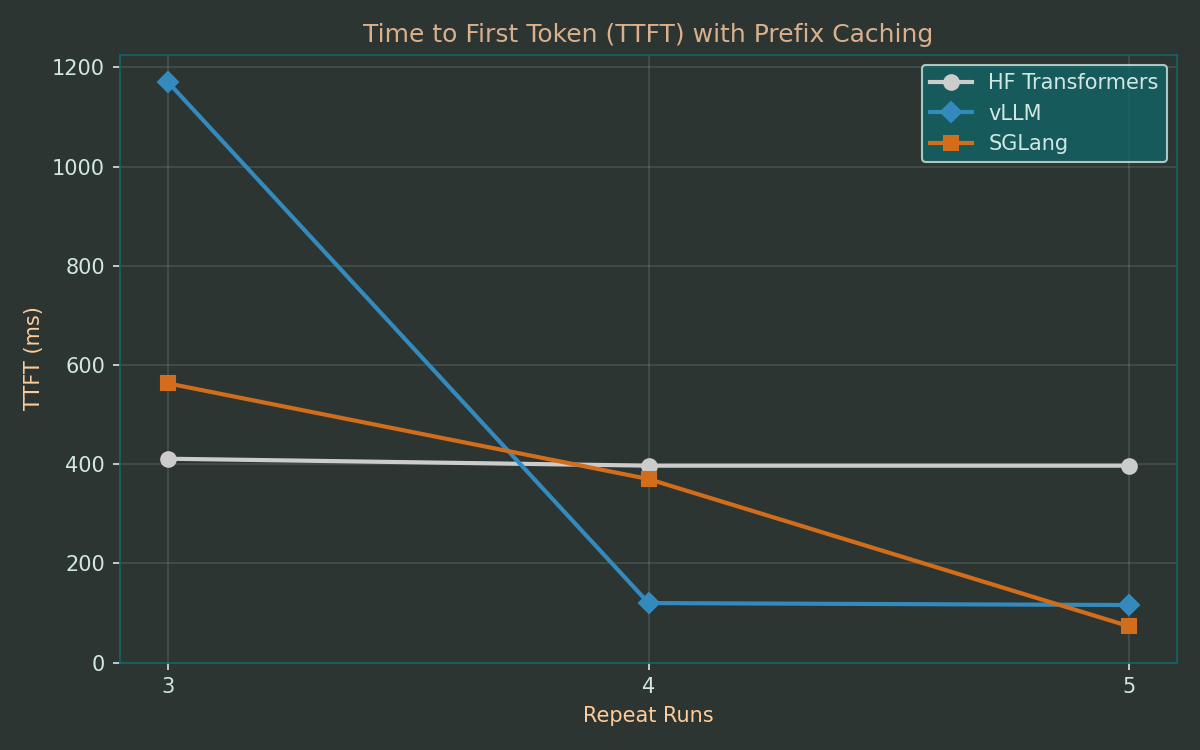
After an initial overhead, both vLLM and SGLang finish the prefill phase much faster than the HFT baseline and reach a TTFT of only 20-30% of the baseline. In the final run 5, the TTFT in SGLang was the same as in the original runs of Experiment 1, running as fast as if no prefix was prepended at all.
On an unrelated but interesting side-note, this experiment also shows Qwen 3.5 successfully handling the divergence attack in the prefix. Its reasoning traces contain outright questions as to whether it is subject to a prompt injection and it proceeds to yield robust responses regardless.
Experiment 4:
For the final experiment, I upgraded to an H100 GPU and the larger model Gemma-4-26B-A4B. This experiment simulates multiple requests coming in, for example from separate users or multi-agent workflows that all use the same serving infrastructure.
For this, both multi-token prediction and prefix/radix caching were disabled. Requests are submitted every 100ms in increasingly large concurrent numbers.
Here, vLLM and SGLang use their continuous batching mechanism, allowing them to include new requests in the batch dimension without having to wait for all sequences in the current batch to be completed. Likewise, they can return sequences once they are completed without having to wait for the other sequences in the given batch. In contrast, the HF Transformers baseline naively queues the requests and processes them sequentially, one at a time. Its latency grows linearly and some of the higher numbers reported below are extrapolated to save on time.
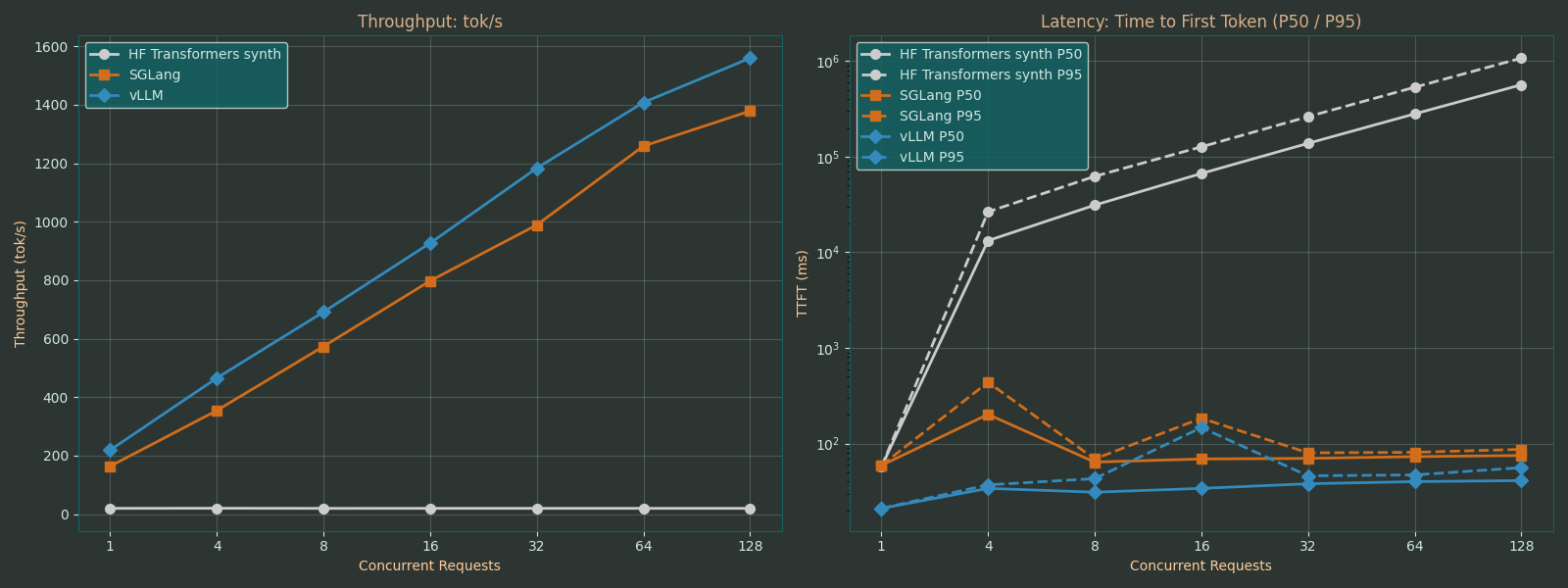
It is for concurrent requests that vLLM and SGLang really show their greatest advantage, scaling to throughputs above 1000 tok/s with no sign of slowing down. Even on the H100, the naive approach only reaches 20 tok/s with the same model when processing incoming requests sequentially.
With 128 concurrent requests, the last in queue would have to wait almost 20min for their response from the naive baseline vs <100ms for vLLM and SGLang.
Discussion
Several of these experiments show a slight edge for vLLM over SGLang, but this is likely down to configuration tuning. For some setups, throughput numbers above 15k tok/s have been reported. A strict and fair throughput benchmarking setup would require more careful tuning, but would have likely burned through the budget on dependency management alone.
Here, I even settled for different CUDA versions for each of the backends, with HF Transformers using the oldest in order to support the highest observed speed. Whereas Ollama and MLX often run out-of-the-box, there were numerous unexpected compatibility issues here that took a bulk of the time to resolve. Trying to think back, I cannot remember the last time I had this many memory issues.
Initially I also meant to have all frameworks produce the exact same output by providing a temperature slider. But even with a temperature of 0 their output diverges due to varying kernel optimizations.
In my own work I have seen this before with convolutional neural networks too. There, inference on CPU vs GPU would flip individual pixels in segmentation masks. However, this typically affected the output measurements by less than a floating point number could accurately represent.
For LLM inference, in contrast, I learned that results in capability benchmark challenges are much more fragile, varying by up to 9% depending merely on choices around hardware, parallelism and batch size.
Conclusion
These experiments only scratch the surface of what the frameworks have to offer. But even in isolation, with a modest budget of time and compute, these features show some impressive acceleration. In practice, they are often complementary and scale even further.
There is also a lot happening on the self-hosting front, even if most consumer-grade hardware will currently struggle to reach the >1000 tok/s seen in experiment 4. For example, vLLM-MLX adapts vLLM features for MLX on Apple Silicon chips. Overall, the software is improving rapidly and it will be interesting to see which use cases will move from API-based access to organisational to even entirely individual and private self-hosting.
Disclaimer: I have no affiliation with any of the listed vendors and this article is not monetized, sponsored or funded in any other way.