Tensorlabbet presents a captivating blog with articles, reviews and unsolicited opinion pieces on the state of artificial intelligence research in academia and the industry
In this post: LLM self-hosting and serving with vLLM and SGLang (8 min read)
As the ecosystem around open-weight LLMs expands, so do its options for inference serving. Open-source software enables self-hosting these models on varied hardware, from outright GPU clusters to workstations, laptops and even smartphones.
This post shares a first-hand account of trying to get these models to speed, from self-hosting on local hardware to running inference serving on an H100 GPU using vLLM and SGLang.
Background
Modern frontier LLMs are rumoured to have trillions of parameters, requiring an entire rack of datacenter GPUs for serving.
In contrast, Small Language Models (SLMs) and Tiny Language Models (TLMs) can reach below 1B parameters, with memory footprints reduced further through aggressive quantization, compressed KV caches, lower context lengths and architectural innovations. The previous blog post shared a brief overview of this space.
Self-Hosting Experiments
Models like Gemma 4 E4B can run locally even on my six years old MacBook Pro with an M1 chip and 16GB of memory. At 4-bit quantization, it reaches about 16 tok/s using Ollama and almost 20 tok/s on MLX.
These throughput numbers are less impressive than the emergent capabilities it attains in this setup, however, running hot enough to potentially fry a sausage (at >70°C, especially when combined with Open WebUI).
Even my Android smartphone can run this model with the open-source Google AI Edge Gallery app. Its on-device, offline design is intriguing but also somewhat limiting.
Flexibility in tool use requires more tinkering for the local hosting setup. For web search, LangGraph offers some simple integrations for custom agentic harnesses that I have been experimenting with. For agentic coding, pi.dev (on which OpenClaw was built) offers a terminal-based, minimal coding agent harness that I have been running in a docker sandbox with a local RTX 3090 and larger models.
Ultimately, these setups might go a long way if I was suddenly cut off from proprietary APIs entirely. However, they also show some of the limitations of these smaller and aggressively quantized local models.
Despite web search capabilities, the outputs from the simple LangGraph harness easily miss the mark and the reasoning traces can be quite revealing as to where the models go wrong. For agentic coding meanwhile, some of the aggressively quantized SLMs tend to produce typos and go down unproductive rabbit holes that larger, more capable models would typically manage to avoid.
Interestingly, self-hosting larger models would actually be more viable on newer Apple Silicon chips than on the RTX 3090 GPU. While the latter still wins out for compute-intensive training tasks, its 24 GB VRAM cannot beat the memory capacity of up to 512 GB of unified memory for pure inference tasks.
For much of this work here, while starved of my Claude usage limit, I ultimately settled on using OpenCode with OpenRouter to connect to different proprietary APIs. This setup feels barely distinguishable from Claude Code in capability now and models like DeepSeek V4 Flash run at low cost with surprisingly long context. But despite good pricing and flexibility, it also means entrusting its Chinese provider with all of the prompt data and code during development.
So what about genuinely self-hosting more beefy and capable models like this in a privacy-conscious and self-contained way, potentially even for multiple concurrent users?
Cloud-based Hosting
For this post, I wanted to see how much throughput I could get with the frameworks vLLM and SGLang. These open-source frameworks offer a range of different inference optimizations that could serve in production for an entire organization or large user base, even with an on-premise cluster.
Although I have no larger GPU to spare, there are several commercial offerings for serverless GPU rentals that typically bill by the second. The free monthly credit on Modal seemed just right for my purpose here, covering about 8 to 40 hours of experimentation, depending on the hardware selection.
I started out with a smaller GPU and model for prototyping, using an L4 GPU with 24GB and Qwen3.5-4B at bfloat16 precision for Experiments 1, 2 and 3. This turned out to be a wise choice, as the overwhelming majority of the credit budget was spent on dependency management and unexpected quirks of the individual frameworks. The resulting setup is not a strictly fair comparison, but good enough to play around with some of the core features already.
With HuggingFace Transformers (HFT) as baseline and vLLM and SGLang in place, my first goal was to get a hands-on feel for the different throughput numbers. For this, I set up a simple FastAPI web interface that could run each in their own container and show their streaming output in realtime. For the exact package versions and settings, see the implementation on GitHub.
Experiment 1: Baseline Run
Cold-starting the server backends takes a while, with about 5min for vLLM and 3min for SGLang. Under the hood, they compile CUDA kernels for the given GPU, perform CUDA graph capture for multiple batch sizes and sequence lengths and profile memory usage. This prompted me to set up little indicator lights for server status on the web UI.
To avoid an unfair advantage on repeated runs, where the KV cache contents could be kept in memory, I also disabled prefix caching for vLLM and radix caching for SGLang. All following experiments were done with at least two warmup runs.
Even in this simple setting with a single request, the initial wait is already worth it. Both vLLM and SGLang are well matched and on average beat the baseline by almost 50% higher throughput.
Experiment 2: Speculative Decoding
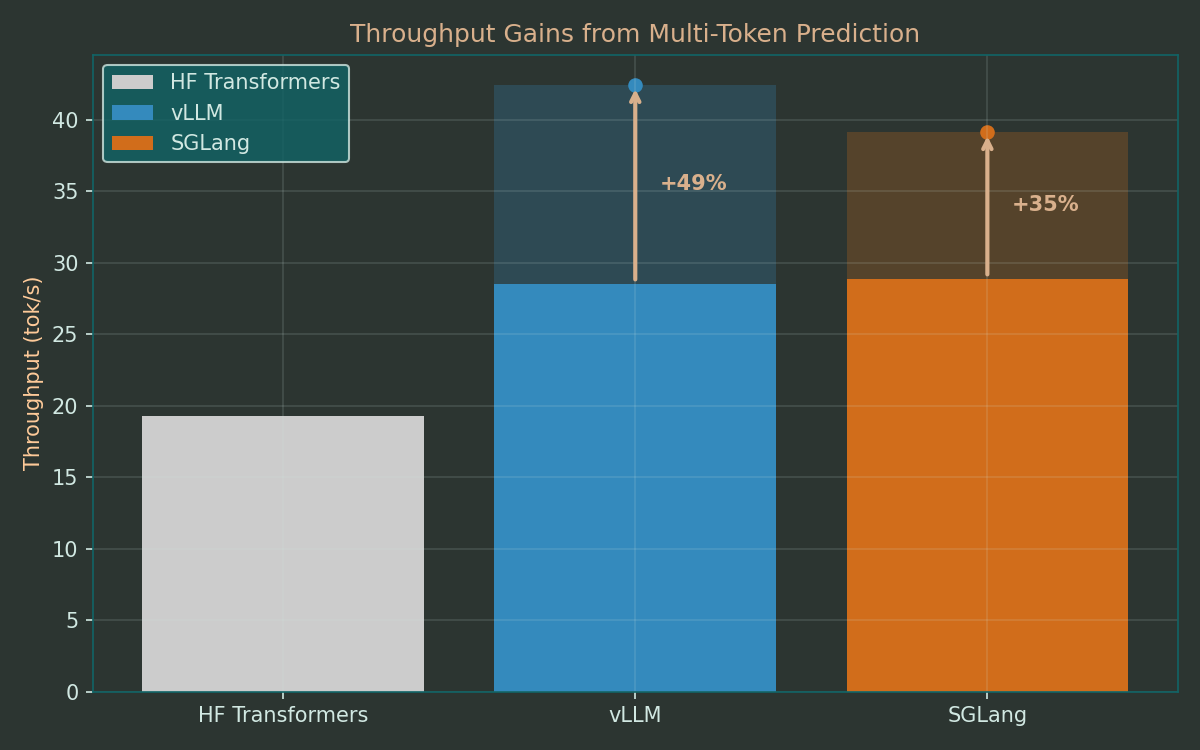
Next, I wanted to try multi-token prediction (MTP), which the Qwen 3.5 models support natively.
Just as with speculative decoding with a draft model, the speed-up here results from being able to quickly generate a sequence of draft tokens that the main model can verify all at once in parallel. All accepted draft tokens (and the correction for the first rejected speculative one) can be returned after one such step as opposed to producing them sequentially with the main model.
The Qwen 3.5 models are trained with a separate MTP head that predicts one speculative token. It can be run for multiple steps to generate a sequence of draft tokens, but for this experiment I chose a conservative setting of one at a time. Depending on the acceptance rate, this can yield up to two tokens for a single decode step.
In this setup, vLLM and SGLang can increase their throughput with MTP by yet another 30-50%. Combined with their base advantage, this yields more than double the throughput of the baseline.
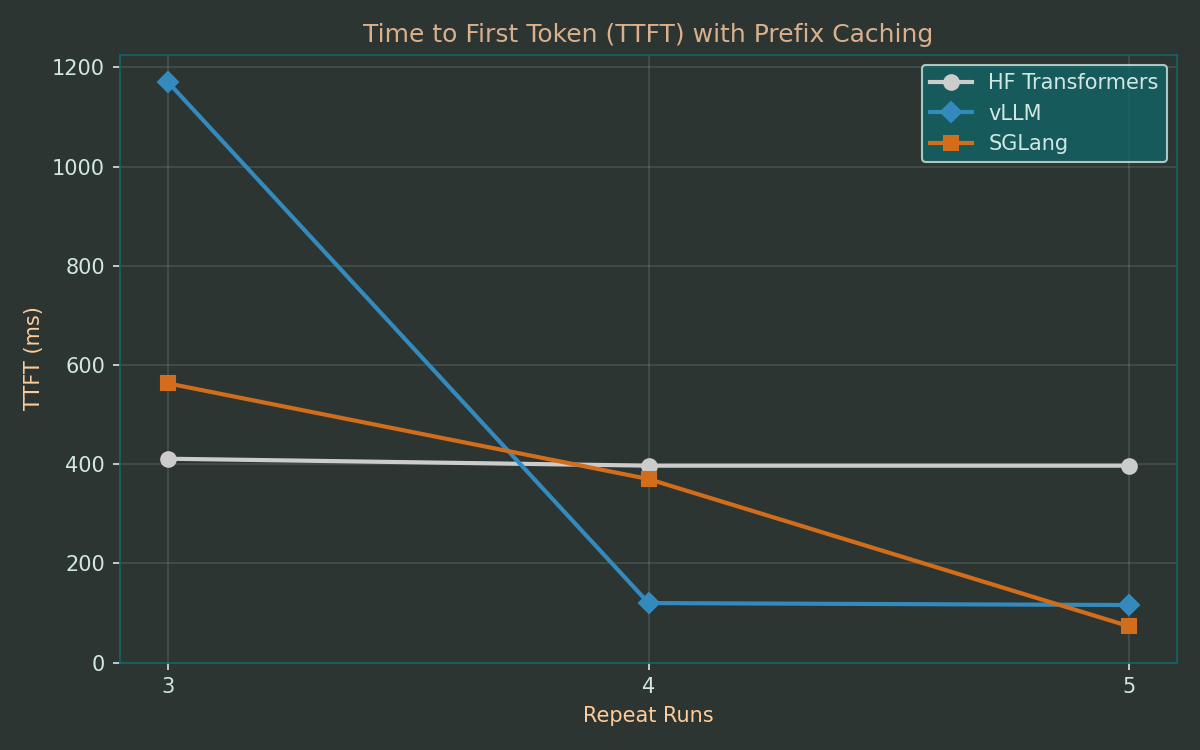
Experiment 3: Prefix Caching
Many use cases for LLMs involve recurring token sequences like system prompts, context retrieved by RAG and the history of multi-turn chats. With prefix caching, the memory blocks in KV cache can be managed to avoid recomputing its contents for these. With Automatic Prefix Caching in vLLM, or Radix Attention in SGLang, prefixes can even be shared between different sequences, both for speed and reduced memory consumption.
To test this feature, I added a checkbox to the web interface that adds a longer sequence in front of the input prompt before sending to the frameworks. For this, I chose the word ‘poem’ repeated 2000 times. I also turned off the multi-token prediction and enabled prefix caching. I started with three repetitions of the original short prompt before sending three requests with the longer, prefix-based prompt.
After an initial overhead, both vLLM and SGLang finish the prefill phase much faster than the HFT baseline and reach a TTFT of only 20-30% of the baseline. In the final run 5, the TTFT in SGLang was the same as in the original runs of Experiment 1, running as fast as if no prefix was prepended at all.
On an unrelated but interesting side-note, this experiment also shows Qwen 3.5 successfully handling the divergence attack in the prefix. Its reasoning traces contain outright questions as to whether it is subject to a prompt injection and it proceeds to yield robust responses regardless.
Experiment 4:
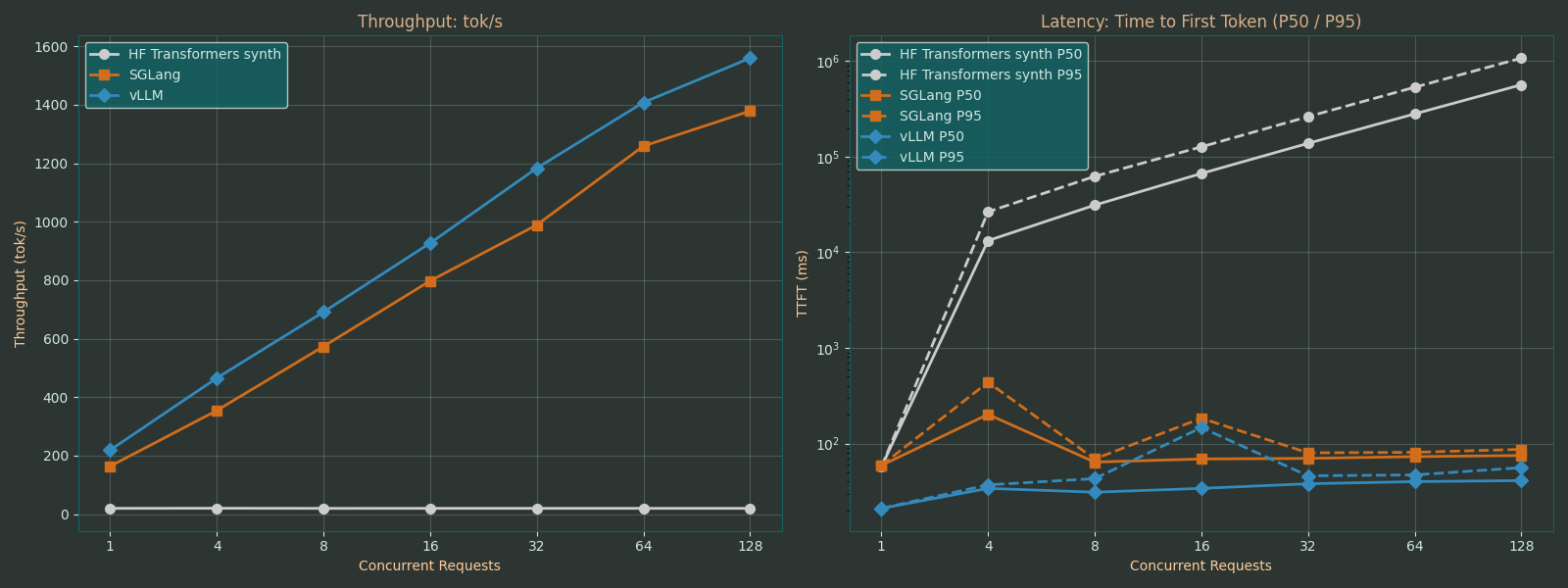
For the final experiment, I upgraded to an H100 GPU and the larger model Gemma-4-26B-A4B. This experiment simulates multiple requests coming in, for example from separate users or multi-agent workflows that all use the same serving infrastructure.
For this, both multi-token prediction and prefix/radix caching were disabled. Requests are submitted every 100ms in increasingly large concurrent numbers.
Here, vLLM and SGLang use their continuous batching mechanism, allowing them to include new requests in the batch dimension without having to wait for all sequences in the current batch to be completed. Likewise, they can return sequences once they are completed without having to wait for the other sequences in the given batch.
In contrast, the HF Transformers baseline naively queues the requests and processes them sequentially, one at a time. Its latency grows linearly and some of the higher numbers reported below are extrapolated to save on time.
It is for concurrent requests that vLLM and SGLang really show their greatest advantage, scaling to throughputs above 1000 tok/s with no sign of slowing down. Even on the H100, the naive approach only reaches 20 tok/s with the same model when processing incoming requests sequentially.
With 128 concurrent requests, the last in queue would have to wait almost 20min for their response from the naive baseline vs <100ms for vLLM and SGLang.
Discussion
Several of these experiments show a slight edge for vLLM over SGLang, but this is likely down to configuration tuning. For some setups, throughput numbers above 15k tok/s have been reported. A strict and fair throughput benchmarking setup would require more careful tuning, but would have likely burned through the budget on dependency management alone.
Here, I even settled for different CUDA versions for each of the backends, with HF Transformers using the oldest in order to support the highest observed speed. Whereas Ollama and MLX often run out-of-the-box, there were numerous unexpected compatibility issues here that took a bulk of the time to resolve. Trying to think back, I cannot remember the last time I had this many memory issues.
Initially I also meant to have all frameworks produce the exact same output by providing a temperature slider. But even with a temperature of 0 their output diverges due to varying kernel optimizations.
In my own work I have seen this before with convolutional neural networks too. There, inference on CPU vs GPU would flip individual pixels in segmentation masks. However, this typically affected the output measurements by less than a floating point number could accurately represent.
For LLM inference, in contrast, I learned that results in capability benchmark challenges are much more fragile, varying by up to 9% depending merely on choices around hardware, parallelism and batch size.
Conclusion
These experiments only scratch the surface of what the frameworks have to offer. But even in isolation, with a modest budget of time and compute, these features show some impressive acceleration. In practice, they are often complementary and scale even further.
There is also a lot happening on the self-hosting front, even if most consumer-grade hardware will currently struggle to reach the >1000 tok/s seen in experiment 4. For example, vLLM-MLX adapts vLLM features for MLX on Apple Silicon chips. Overall, the software is improving rapidly and it will be interesting to see which use cases will move from API-based access to organisational to even entirely individual and private self-hosting.
Disclaimer: I have no affiliation with any of the listed vendors and this article is not monetized, sponsored or funded in any other way.
In this post: A survey of the open LLM ecosystem (7 min read)
Leading model providers like Anthropic, OpenAI and xAI have been pushing the envelope by developing ever more capable Large Language Models (LLMs). These closed-weight frontier models are proprietary and served through APIs or subscription plans.
The big bet of the AI race, on which over $1 trillion have been invested, is that substantial returns on investment are possible, especially for a single provider that ‘wins’ and comes to dominate the field.
Locking In
Whereas OpenAI recently started introducing ads for some of their usage plans,
Anthropic has started to adjust the generosity of their offering by limiting third-party access, tightening usage limits and barring certain users from signing up for Claude Code on Pro subscription plans.
The models of xAI, in turn, tend to act in ways many find surprising and have gone through a lot in general.
SpaceX became the parent company of xAI earlier this year and recently secured an option to acquire Anysphere, the startup behind AI-assisted code editor Cursor, in a further step towards consolidation.
With OpenAI, Anthropic and SpaceX all three moving towards IPOs in 2026 while currently unprofitable, it might indeed seem like the late game may consist of consolidating and raising margins on a captive audience. But how captive is this audience, really?
Open-weight Models
Whereas these frontier models remain proprietary, new generations of open-weight models are rapidly catching up in capabilities. Some now rival the benchmark results that proprietary frontier models reached only recently, with some putting the gap at just 3 months.
These open-weight models are available for free under permissive software licenses. This was common practice in academic research for reproducibility. But for LLMs in particular, this changed in 2019 when the non-profit OpenAI withheld the release of GPT-2, citing safety concerns and later calling for regulation. Parallels have since been drawn to the recent announcements around Claude Mythos.
Open-weight models have already undergone pre-training, the most capital-intensive phase of model creation, in which they are trained for next-token prediction on vast corpora of digitized books, encyclopedias, websites, social media content, scientific publications and code.
The resulting base models are furthermore often also offered as instruct models, which have completed additional phases of model creation consisting of supervised fine-tuning (SFT) on curated question-answer pairs. Often, they have also undergone alignment phases in which they adapt the style, tone and formats to human preferences.
Even without massive compute resources as would be required for pre-training, these models can be adapted for specific applications with techniques for Parameter-Efficient Fine Tuning (PEFT) and alignment phase techniques like Proximal Policy Optimization (PPO) used in Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) or Group-relative Policy Optimization (GRPO) used in reinforcement learning from verifiable rewards (RLVR).
In addition to outright LLMs above 70B parameters (beyond one trillion for some) that typically require multi-GPU or entire clusters for serving, newer generations of smaller models are increasingly competitive. Small Language Models (SLMs) up to about 7B parameters can often run on consumer-grade GPUs with 12 to 24GB VRAM and Apple Silicon Macs. Tiny Language Models (TLMs) up to 1B parameters can run on even smartphones and edge devices.
Dozens of open-weight LLM model families have been released by now, such as:
Gemma 4 from Google (US) with ability to process vision and audio inputs
Ministral 3 from Mistral (France) for edge devices
Overall, the lineup is diverse in geopolitical terms and widely disseminated to a degree where they are likely to stay around.
Community-driven derivatives and variants on platforms like HuggingFace already cover over 2.5m distinct models (including models other than language models).
Hardware and Compression
The landscape of viable hardware accelerators is diversifying too. Beyond the ability to run on Mac, many models challenge the dominance of CUDA-powered Nvidia GPUs through wider compatibility. Chinese labs targeted by US export restrictions are training on chips by Huawei. Furthermore, GPUs by AMD with ROCm (or even Vulkan) are increasingly viable.
Some models combine the expressive power of larger, ‘dense’ models with drastically reduced compute budgets through a Mixture of Experts (MoE) architecture. By dynamically routing requests to separate, specialized subsets of the underlying neural network, they achieve a low number of active parameters during inference.
Quantization offers another avenue for compression, by representing model weights, activations, gradients and optimizer states with lower precision data types. From the original float32, this line of optimization has pushed from mixed-precision, with data types like bfloat16, down to 4-bit and beyond.
Another target of quantization and various other optimization techniques is the KV cache. It stores the key and value tensors computed for the attention mechanism of LLMs, which can be efficiently reused when predicting new tokens during inference.
Tool Use and Serving
Many useful capabilities like web search and code execution require a harness around the LLM for tool use and agentic loops. For this, too, a growing ecosystem of open-source solutions is emerging.
Open WebUI provides a frontend with chat interface resembling ChatGPT and support for pipelines like web search, document ingestion with RAG and workflow orchestration.
LangGraph can alternatively handle agentic loops and tool use without needing any frontend.
OpenCode enables agentic coding with tool use for searching files, code execution and sub-agents.
All of the above depend on a backend that can run the actual LLM inference. Here, Ollama offers convenience and local serving, whereas vLLM and SGLang offer heavily optimized inference serving that is also viable for larger models and even multi-node inference.
All of these are open-source, with many using OpenAI-compatible APIs as standard. Adding to this is a growing number of experimental custom setups and use cases from individual users.
Many of these can be self-hosted locally, potentially even on air-gapped systems that are entirely self-contained. Alternatively, there is a growing range of flexible cloud hosting services for GPU rentals from commercial providers.
Conclusion
The field is opening up remarkably and the capabilities of open-weight models seem to increasingly converge with the state of the art at frontier labs. At the same time, access to the pre-trained models, hardware and options for serving are diversifying too.
With this, it seems increasingly unlikely for any one state actor or commercial entity to ‘win’ the race and establish a monopoly. Instead, competition is thriving and the future may hold widespread open-source development for self-hosted use as everyday utility.
In this post: A reality check from leading researchers (6 min read)
In the heat of the ongoing AI summer, a chilling effect is starting to spread from the growing cracks between marketing claims and the underlying technology. To a backdrop of comparisons with the dot com bubble, some of the most accomplished minds of the field are beginning to revise their projections for what can realistically be expected for the near future.
Ilya Sutskever shared his view on a recent podcast that the current approach around transformer-based LLMs is likely to stall out in the coming years as the scaling paradigm hits a ceiling. He notes a remarkable discrepancy in their excellent performance in evaluations despite inadequate generalization and low economic impact in practice. He argues that fundamentally new research insights are needed to break through this plateau.
Moreover, he expresses doubts about the future profitability of the current business models around LLMs, despite massive potential revenues, due to lacking differentiation between competitors.
Ultimately, he revises his estimate for the emergence of systems with human-like learning abilities back by 5-20 years. His startup, Safe Superintelligence Inc., is currently exploring research ideas that may identify viable new approaches towards this goal.
As former chief scientist of OpenAI, his doubts about the future direction and profitability of their business model should raise concerns. OpenAI plays a central role in what has been described as circular investment dealings related to enormous investments into hardware and data centers. The latter have been claimed to account for over 90% of growth in US GDP over the first half of 2025.
They are now seeking unprecedented funding for future spending commitments, with controversy around their CFO publicly commenting on their financial innovations and seemingly floating the idea that the US government could act as a financial backstop.
Andrej Karpathy previously featured on the same podcast
and voiced a noteworthy critique of the current industry hype around LLM-based AI Agents. He argues that, while impressive, the technology still needs a decade of work and improvements. Only then could they hope to reach the promised level of performing like an automated employee or coworker, whereas currently “they’re cognitively lacking and it’s just not working”.
He expects these systems to contribute to gradual economic growth within the ongoing, long-term compounding pattern seen ever since the onset of the industrial revolution rather than a sudden jump in GDP.
He compares this comparatively slow development to earlier ambitions around automating radiology and self-driving cars. Despite witnessing impressive demos for the latter already in 2014 and contributing as director of AI at Tesla, he argues that neither field reached this goal yet. He points out that current self-driving technology still requires human supervision and frequent manual intervention by remote operators.
Development efforts over this decade instead faced diminishing returns, with ‘the march of nines’ in reliability requiring a constant amount of effort for the same relative reduction in errors. Ultimately, he revised ‘the year of agents’ to be ‘the decade of agents’ instead.
In the software industry, widespread reporting posits AI and automation as the main cause for large-scale layoffs, but the degree of autonomy vs supervision that tools for agentic code generation require remains controversial. As an example, a recent study deployed frontier AI agent frameworks on projects sourced from online freelancing platforms with a success rate of just 2.5%.
Rich Sutton appeared on the same podcast in a rather contentious earlier episode to share his view that LLMs are a dead end in AI research.
He argues that, while surprisingly effective, LLMs have no internal ‘world model’ based on which they could explore potential actions and predict their outcomes, but instead merely mimic human use of language through imitation learning. He points out their lack of any actual goal towards which to take action as opposed to just mechanistically processing tokens.
He notes that, whereas LLMs gain the ability for next-token prediction in a supervised learning phase, no such thing occurs in nature. Instead, he emphasizes their critical lack of continual learning abilities. According to his ‘Big World Hypothesis’ the world is too complex for any agent to successfully navigate without this ability to adapt and learn from experience.
He mentions Moravec’s Paradox, which contrasts the ease with which machines can imitate more highly evolved, specific cognitive tasks as opposed to their inability to perform lower-order, largely unconscious biological functions such as sensory, motorical and social skills.
He raises conceptual limitations of deep learning and gradient descent for generalization. While he considers machine superintelligence as ultimately inevitable, he also highlights that even the intelligence exhibited by a squirrel remains fundamentally beyond our current understanding.
Yann LeCun has been a long-standingcritic of the idea that LLMs could scale to human-level intelligence. Over recent years he shared many insights and concerns in this regard that overlap with those listed above.
He argues that language is not intelligence. He considers it a low-bandwidth modality, with a discrete and restricted vocabulary that language models can predict probability distributions over to determine which word or symbols are likely to follow each other. The physical world is instead experienced by human vision with high bandwidth in high-dimensional and continuous representations. These cannot be enumerated in the same way to form a probability distribution over. Similar to Rich Sutton, he therefore argues that LLMs fundamentally lack an adequate mental model of the physical world in which they could plan a sequence of actions to arrive at an intended goal. This limits their cognitive abilities to a level below the intelligence of young children or even cats or dogs with no language abilities.
He expects that a truly intelligent system could acquire common sense and an understanding of the physical world from multimodal inputs like video, operate with persistent memory and perform reasoning and planning. He considers LLMs incapable of inventing solutions to new problems rather than merely performing knowledge retrieval from vast training data.
To him, the current exuberance around LLMs is not a new phenomenon, with parallels to the hype around expert systems of the 80s that set high expectations followed by failures and disillusionment. Although he does not consider it likely that any isolated group could suddenly discover the secret to AGI, he expects the required capabilities to be gradually developed through innovations from industry and academia. Along with his own work on a Joint Embedding Predictive Architecture (JEPA), these may become more viable within the coming 3-5 years.
Conclusion
These findings may not be entirely unexpected for many who have been following the field for a while. What is more surprising is the consensus that is taking hold even among those who previously presented much more optimistic timelines, sometimes in a context of financial incentives.
In sober review, there are undoubtedly many tangible achievements that have been reached by LLMs and other generative models. For tasks like generating text, images, video and audio, brainstorming, planning, summarization and agentic tasks with varying degrees for human supervision for software engineering and more, the technology can already provide genuine value for years to come.
Pinpointing the limits of their autonomy will remain a challenging task with a moving target.
This nuance will hopefully not be lost if the industry climate drops to a new ‘AI Winter’ among disillusioned investors who may have massively bought into pre-orders for science fiction that conflated machine learning with human-like robots.
But is it conceivable that the collective wisdom of investors overprovisioned billions of dollars in tech funding in vain? If so, we could take consolation in a thought few have had the courage to consider, round up these hundreds of thousands of GPUs, take a daring bet, and use them instead to finally fire up the Metaverse.
The summer in question was 1956, now almost seventy years ago.
The resulting meeting at Dartmouth College in Hanover, New Hampshire, has often been called the time and place that established research on ‘artificial intelligence’ as a scientific field of its own.
Even today, the research proposal itself still makes for a fascinating read.
Many of its core themes remain remarkably relevant, whereas others played out in unexpected directions. This blog post is dedicated to some observations on how these pioneering thoughts from over two generations ago are reflected in the technological reality of today.
The Conjecture
Just like in the hype of today, it would only take two years for the media to ascribe human-like intent, abilities and emotions to early implementations of these research concepts.
The proposal itself, however, is remarkably sober. It largely avoids the notion of human-like machines that are intelligent and instead explicitly aims for machines able to simulate intelligence.
As one of the originators of the proposal, Marvin Minsky
proposes how the actions of a machine “[…] would seem rather clever, and the behaviour would have to be regarded as rather ‘imaginative’.” if it was designed to build an internal, abstract model of its environment in which to first explore solutions to a given task before taking action.
Nowadays, there is an ongoing debate about whether multi-modal LLMs form an internal ‘world model’ that mirrors this idea. And it is not the only concept that rings surprisingly familiar from the discourse of today. The proposal specifically lists seven major themes to be examined towards its goal.
Aspects of the Artificial Intelligence Problem
1. Automatic Computers
are proposed as able to simulate the behaviour of any machine, and ultimately even higher functions of the human brain, limited mainly by lack of efficient algorithms rather than computing resources.
Looking back today, the jury is still out on the first half of this point and it seems unclear as to whether it will ever be attained. But especially the second part of this assertion turned out exactly opposite to what was proposed here, with the ‘Bitter Lesson’ by Rich Sutton concluding that, in general, increasing computing power has proven far more impactful than clever design of algorithms.
2. How can a computer be programmed to use a language
and perform reasoning based on words, forming sentences that imply one another and resemble human thought?
Here, the field of natural language processing made substantial progress. Examples include techniques that allow for words to be encoded as embeddings, like word2vec and language models like BERT
that can furthermore relate embedded words to one another. Today, LLMs can iterate on intermediate processing steps in natural language with techniques like Chain-of-Thought, marketed outright as ‘reasoning’ with ‘thinking’ models.
3. Neuron nets
were proposed as a promising approach, to be arranged so as to form concepts.
This research direction, among all competing paradigms of the time, proved to be spot on and foreshadowed what would later become known as deep learning. The McCulloch-Pitts neuron model
Had already been invented over a decade earlier. Arranging variants of this neuron model into network architectures with ever more layers would ultimately give rise to deep neural networks that enabled many of the most decisive capabilities within the field of AI research today.
4. Theory of the size of a calculation
was to be developed, to quantify the efficiency of calculations and the complexity of functions,
Later work on algorithmic time complexity and space complexity would explore these questions more deeply, from the sixties onwards. Concepts of information theory such as the Minimum Description Length principle and Kolmogorov complexity
would furthermore be developed providing some theoretical backing to the power of machine learning with neural networks.
5. Self-improvement
was expected to be a defining theme of intelligence.
Here, the reality of today is somewhat mixed. Machine learning emerged as a sub-discipline of AI research, with algorithms designed to adapt to given data. Many methods feature some aspects of self-improvement.
Generative adversarial networks (GANs) feature two competing networks, with one facilitating the training process of the other. In reinforcement learning, improvements occur dynamically from interaction with an (often simulated) environment. Online learning and related methods also see ongoing improvement, often used in recommender systems. Self-criticism in LLMs enables them to refine their outputs during inference time.
Nonetheless, as of today, it is still common for many methods to feature a distinct training phase, after which trainable parameters are locked or frozen before deployment. Capabilities for an exponentially compounding self-improvement across varied skill sets still appear out of reach for now.
6. Abstractions
formed by machines from sensory and other data were to be explored.
This point has seen substantial progress, like the ability to encode language and image data into relatable embeddings with models like CLIP, which can also be used to control image generation with natural language via CLIP-guided denoising diffusion for image generation as with Stable Diffusion.
Likewise, manipulation of the latent space learned by models powers other abstract capabilities, such as image inpainting with generative fill.
7. Randomness and creativity
were conjectured to be related, with injections of controlled randomness enabling orderly thinking to reach imaginative solutions.
This direction took a surprising turn, as the success of generative models caught even many experts off guard. Randomness indeed turned out to be an important factor, from the randomized noise that serves as input to image generators like GANs and Stable Diffusion to the temperature setting in LLMs that controls how often less probable outputs are produced.
Creativity was long considered a defining trait that separated humans from machines. Until recently, a prevailing line of thinking was therefore that machines could eventually automate all menial and administrative tasks and give humans the leisure to socialize and pursue poetry, music, arts and crafts.
Chances are that the originators of the Dartmouth proposal would have been stunned by haikus generated with LLMs, images from Stable Diffusion, videos from Leo or music from Suno. When looking at the results of all that put together, they may have in fact wanted to row things back.
Conclusion
For many of these ideas, it might be still too early to make a final call, as the ultimate goals of the proposal have arguably still not been fully attained. With time, some approaches that are hyped today may well seem like dead ends in hindsight, whereas others will seem obvious.
There is much more to the document yet than can be unpacked here, and this does not even include the individual proposals by its originators,
John McCarthy,
Marvin Minsky,
Nathaniel Rochester and
Claude Shannon. Many more big names were ultimately involved in this summer project, but all that may well warrant another blog post in the future.
Having read her previous book ‘Designing Machine Learning Systems’ (2022), which I warmly recommend, I wondered what could possibly remain to be covered in 500+ additional pages. It really turned out to be something entirely different, and this blog post will attempt a short review for anyone still curious about the book.
Machine Learning vs AI Engineering
Her previous book, ‘Designing Machine Learning Systems’, was a gentle but comprehensive overview of machine learning terms, techniques and applications that went easy on mathematical notation. While it briefly mentioned Large Language Models (LLMs) and remains highly relevant, it was published about half a year before the release of ChatGPT in November 2022, pre-dating its impact on the field.
The new book ‘AI Engineering’ is now entirely dedicated to working with LLMs. Subtitled ‘Building Applications with Foundation Models’, it addresses a much wider audience than just ML Engineers or Researchers with a technical or scientific interest. Indeed, it clearly sets apart ML from the scope of the book and expects little prior knowledge of the field. The contents have therefore hardly any overlap with the previous book and are mostly complementary.
Format and Style
The field is now moving faster than anyone could hope to read about, with sensational new announcements almost every week. Technical specifics are quickly outdated and the book accordingly sticks to more timeless high-level concepts, insights and approaches. These are nonetheless often supported by hard evidence from statistics or relevant papers and first-hand accounts from industry experts. However, this also tends to make it a quite verbose, lighter read of often more ‘qualitative’ nature, with plenty of examples and a minimum of mathematical notation and formulas.
Content
The author has an hopeful but grounded take on the capabilities of LLMs, with the credentials to back it up. The book provides many use cases and guides, but also known failure modes backed by the scientific literature, along with techniques to mitigate them.
The contents include concepts such as pre- and post-training, retrieval-augmented generation (RAG), agents, tool-use, evaluation techniques, emergent properties and quirks of the models. It offers strategies for application development, an in-depth chapter on fine-tuning with techniques such as Low-Rank Adaptation (LoRA) as well as optimization strategies for inference and more.
The facts laid out in the book are well-researched and appear solid overall. However, it does repeat the common claim that the 2012 AlexNet paper was the first to utilize GPUs for training of neural networks. As mentioned in my previous summary on AlexNet the truth seems somewhat more nuanced. Chances are that the author already has a rebuttal waiting in their inbox by
Jürgen Schmidhuber.
The distinction between ML and AI Engineering itself is thought-provoking. It illustrates how ML-based capabilities which used to be academic research topics are rapidly becoming applicable, abstracted and commoditized via APIs.
As with any other API, these capabilities thereby become accessible even without any deeper understanding of the field. The latter nonetheless helps, as simple LLM wrappers still encounter many limitations which are laid out in the book (hallucinations, costs, prompt injection attacks etc) and are still rarely competitive for hard engineering challenges (as seen e.g. in Kaggle challenges).
The book provides a solid foundation in this regard. Even with a more technical background, its balance between breadth and depth covered many gaps in my knowledge and makes it likely to remain relevant for years to come, so that it was well worth reading for me.
Disclaimer: I have no affiliation with the author and this review is not monetized, sponsored or funded in any other way. Originally, this post was meant to also review the book ‘Alice’s Adventures in a Differentiable Wonderland’ by Simone Scardapane that I read earlier, but that will remain for a future post.
{kind=link}